Chapter 6: From Meat to Metal
Chapter Primer
Your company runs on 50TB across 200 normalized tables. Ten thousand queries per second. You can't shut it down to rebuild. Evolution faced the same problem when consciousness required different architecture than reflexes—the solution wasn't replacement, it was wrapping.
- The 0.3% coordination tax (market microstructure that unlocks when position equals meaning)
- F-category economics (economic value trapped in synthesis grinding, freed by wrapper pattern)
- The [⚪I1🎯 Discernment](/book/chapters/glossary#i1-discernment) → [⚪I2✅ Verifiability](/book/chapters/glossary#i2-verifiability) → [⚪I6🤝 Trust](/book/chapters/glossary#i6-trust) cascade (three unmitigated goods that unlock sequentially, not independently)
- BCI predictions (why consciousness-compatible interfaces require S≡P≡H substrate)
By the end: You'll recognize the migration path that preserves production while unlocking $14K annual ROI in 4 weeks—and why faster Unity Principle adoption beats AGI timeline risk.
Spine Connection: Evolution solved the Villain problem: how do you preserve the reflex (cerebellum) while building the ground (🟣E4a🧬 Cortex)? Answer: 🟤G1🚀 Wrapper Pattern, not replacement. The cerebellum doesn't disappear—it becomes the substrate the cortex wraps. The Solution is the Ground: 🟢C2🗺️ ShortRank wraps your normalized legacy while delivering 🟢C1🏗️ Unity Principle (S≡P≡H) alignment. Zero code changes. Immediate value. Gradual migration. You're the Victim only if you believe "rip and replace" is the only option. Evolution proved otherwise 500 million years ago.
Epigraph: You can't migrate what you can't stop. And you can't stop what keeps you alive. Production runs now. Ten thousand queries per second. Revenue flowing through normalized tables. Fifty terabytes across two hundred schemas built over fifteen years. Your company's blood supply. Cut it and you die. This is the migration paradox. The same one evolution faced five hundred million years ago when consciousness required different architecture than reflexes. Cerebellum worked - balance, heartbeat, survival. But consciousness needed zero-entropy substrate. Needed semantic neighbors co-located. Needed precision above ninety-nine-point-seven percent. Evolution couldn't stop the cerebellum to rebuild it. You can't stop production to denormalize. The solution: wrapper. Not replacement - augmentation. Build the new architecture atop the old. Cortex wrapped cerebellum. Preserved reactive substrate. Added discovery layer above maintenance layer. Both run simultaneously. One compensates for entropy. One eliminates entropy at source. The gothic part? Parts of you die during this. The cerebellum is vestigial for consciousness - sixty-nine billion neurons contributing zero awareness. Evolution paid the metabolic cost because consciousness requires it. Your migration will have vestigial components too. Normalized tables still running underneath. Wrapper translating between architectures. Inefficiency tolerated temporarily because transformation cannot happen all at once. Watch the metabolic cost. When cortex first emerged, it consumed fifty-five percent of brain budget - massively inefficient compared to cerebellum's ten percent. But the value wasn't efficiency. It was capability. Consciousness. Insight. The ability to measure drift instead of blindly compensating for it. Your wrapper will be expensive at first. Dual architectures. Translation layers. But the value isn't cost savings. It's measurement capability. Drift visibility. Trust equity building instead of trust debt compounding. The old architecture doesn't disappear. It becomes the substrate the new architecture wraps. And eventually - after enough cache hits, enough flow states, enough precision collisions - the old way becomes vestigial and the new way becomes inevitable. The phase transition: the moment when building verifiable systems becomes worth attempting. Evolution crossed it. Your migration crosses it. Once verification is tractable, you build what was always possible but never tried.
Welcome: This chapter solves the migration paradox—you can't shut down production to rebuild, but evolution already showed the path. You'll discover the wrapper pattern that preserved cerebellum while building cortex, understand the ShortRank facade delivering 26×-53× faster performance with zero code changes, and see the ⚪I1🎯 Discernment → ⚪I2✅ Verifiability → ⚪I6🤝 Trust cascade unlock sequentially.
SPARK #25: ⚪I1🎯 Discernment → ⚪I2✅ Verifiability → ⚪I6🤝 Trust
Dimensional Jump: Discernment → Verifiability → Trust Surprise: "Three separate 'nice-to-haves' are actually SEQUENTIAL UNLOCK - each enables next!"
The Migration That Doesn't Kill Production
You can't shut down the plane to replace the engines. Production runs now. Ten thousand queries per second. Fifty terabytes across 200 normalized tables built over 15 years. Your company's blood supply. Cut it and you die. This is the migration paradox—and evolution already solved it.
Evolution's solution: wrapper, not replacement. Cerebellum worked (balance, heartbeat, survival), but consciousness needed different architecture—zero-entropy substrate with semantic neighbors co-located. Evolution couldn't stop the cerebellum to rebuild it. Solution: cortex wrapped cerebellum. Both run simultaneously. One compensates for entropy (reactive substrate). One eliminates entropy at source (discovery layer).
The ShortRank facade pattern. Application → ShortRank cache → Normalized DB (legacy). Zero code changes. Cache hits return instantly (S≡P≡H-aligned, meaning preserved). Cache misses query legacy DB, synthesize result, cache for next time. Transparent wrapper. Immediate value: 26×-53× faster (Chapter 3 numbers). Gradual migration as cache coverage grows.
Watch for the vestigial cost. When cortex first emerged, it consumed 55% of brain budget [→ A5⚛️]—massively inefficient compared to cerebellum's 10%. But the value wasn't efficiency—it was capability. Consciousness. Insight. The ability to measure drift instead of blindly compensating. Your wrapper will be expensive at first (dual architectures, translation layers), but the value isn't cost savings—it's measurement capability [→ E6🔬].
By the end, you'll understand the unmitigated goods cascade. Discernment → Verifiability → Trust. Three separate "nice-to-haves" are actually sequential unlocks. Each enables the next. The phase transition: when verification becomes cheaper than speculation, you build what was always possible but never tried.
The through-line from Chapter 1 to Chapter 6:
Chapter 1 defined Unity Principle mechanism: position = parent_base + local_rank × stride applied recursively. Chapter 4 showed wetware implementation (cortical neurons co-located, Hebbian wiring, qualia as alignment detection). Chapter 6 shows hardware implementation—the SAME pattern in silicon.
Not analogy. Substrate independence:
- [Chapter 1](/book/chapters/01-unity-principle): Formula (abstract mechanism)
- [Chapter 4](/book/chapters/04-qualia-substrate): Neurons (biological substrate)
- **[Chapter 6](/book/chapters/06-from-meat-to-metal): Cache lines (silicon substrate)**
The wrapper pattern succeeds BECAUSE hardware already implements Unity Principle naturally. We're not imposing a pattern—we're aligning with what the CPU does anyway. Sequential access, cache locality, prefetching—all emerge from compositional nesting at the physics level.
The Question After Recognition
You've felt the gap.
Your meat implements S≡P≡H (cortical neurons co-located, cache hits, flow states).
Your metal violates it (normalized databases, synthesis grinding, cognitive load).
The obvious answer: "Migrate everything to Unity Principle. Rebuild from scratch with S≡P≡H."
The problem with obvious answers: Your company runs on those normalized databases RIGHT NOW.
- Production traffic: 10,000 QPS
- Customer data: 50TB normalized across 200 tables
- Team knowledge: 15 years of schema evolution
- Integration points: 40 microservices depend on current structure
You can't just shut it down and rebuild.
But you also can't keep running systems that accumulate 66.6% Trust Debt degradation per 365 decisions.
The Migration Paradox
"Big Bang Rewrite" → Months of planning → Feature freeze → Parallel implementation → Cutover weekend → Everything breaks → Roll back → Resume normalization
You're trying to change the substrate WHILE the system runs on it.
Like replacing airplane engines mid-flight.
Inevitable result: Crash.
The Unity Principle approach (works):
Don't replace the substrate.
The Wrapper Pattern (ShortRank as Facade)
Application → Normalized DB (200 tables, foreign keys, JOINs)
Problem: Semantic ≠ Physical (symbols dispersed, cache misses, synthesis required)
Application → ShortRank Facade → Normalized DB (legacy)
↓
(Cache layer implements S≡P≡H)
- **Receives query** from application (no code change!)
- **Checks cache** for S≡P≡H-aligned result
- **Returns result** to application (transparent wrapper)
Nested View (the wrapper pattern flow):
🟤G1🚀 Wrapper Pattern ├─ 🟡D1⚙️ Application Layer (unchanged) │ ├─ Sends query as normal │ ├─ Receives result as normal │ └─ Zero code changes required ├─ 🟢C2🗺️ ShortRank Facade (new layer) │ ├─ Receives query │ ├─ Checks 🟢C1🏗️ S=P=H-aligned cache │ ├─ On HIT: return instantly (🟣E1🔬 P=1 Mode) │ └─ On MISS: query legacy, cache for future └─ 🔴B2🚨 Normalized DB (legacy, unchanged) ├─ Still exists, still works ├─ Becomes write-only archive over time └─ Zero migration risk
Dimensional View (position IS meaning):
[🟡D1⚙️ Application] ------> [🟢C2🗺️ ShortRank Facade] ------> [🔴B2🚨 Normalized DB]
| | |
Dimension: Dimension: Dimension:
INTERFACE TRANSLATION STORAGE
| | |
Unchanged Position = Meaning Legacy
(zero code (🟢C1🏗️ S=P=H cache) (preserved)
changes) | |
HIT: 8-15ms (🟣E1🔬 P=1) MISS: 200-800ms
MISS: query+cache (falls through)
What This Shows: The nested view presents wrapper as a layer cake to implement. The dimensional view reveals WHY it works: interface unchanged means no disruption, translation layer provides S=P=H benefits, storage preserved means no risk. Each dimension can be optimized independently. The facade IS the migration path because it lets you transform ONE dimension (cache alignment) without touching the others.
Why this works at the physics level:
The wrapper implements Unity Principle's core mechanism:
Position = parent_base + local_rank × stride
Applied recursively at all scales:
- **Cache line:** Address = base + offset × line_width (hardware [→ D2⚙️])
- **Cortical column:** Activation = region + neuron × spacing (wetware)
- **ShortRank:** Customer = tier + affinity × interval (database)
S≡P≡H IS Grounded Position—not an encoding of proximity, but position itself via physical binding. The brain does position, not proximity. Hardware cache locality isn't an optimization—it's alignment with reality. Your CPU already implements Unity Principle. ShortRank just exposes it to application layer. Coherence is the mask. Grounding is the substance.
Zero disruption: Application code unchanged Immediate value: Cache hits = 26×-53× faster (Chapter 3 numbers) Gradual migration: As cache warms, more queries hit S≡P≡H path Measurable ROI: Cache hit rate = Unity Principle adoption metric Reversible: If it fails, remove wrapper (no data lost)
The Information Physics: Why 26×-53× (and Why 361× is Possible)
The amplification mechanism isn't magic—it's the gap between two types of information:
Shannon Entropy (H): Information needed to TRANSMIT the pattern
- Normalized databases force sequential synthesis
- Each JOIN operation pays the full Shannon entropy cost
- H = 65.36 bits must be transmitted serially
- Result: P<1 mode, slower processing
Kolmogorov Complexity (K): Information needed to RECOGNIZE the pattern
- ShortRank facade enables holographic recognition
- Pattern grammars compress understanding to K bits
- For experts: K → 1 bit (instant recognition)
- Result: P=1 mode, t→0 processing
A = Shannon / Kolmogorov = H / K
Measured performance:
- Novice systems (K ≈ 65 bits): A ≈ 1.0× (no gain)
- Basic cache (K ≈ 8 bits): A ≈ 8.2× (modest gain)
- ShortRank (K ≈ 2.5 bits): A ≈ 26× (measured lower bound)
- Optimized (K ≈ 1.2 bits): A ≈ 53× (measured upper bound)
- Master (K → 0.18 bits): A → 361× (theoretical maximum)
Nested View (Shannon vs Kolmogorov information types):
🔵A3⚛️ Two Types of Information ├─ 🔴B3🚨 Shannon Entropy (H) │ ├─ Definition: Information needed to TRANSMIT the pattern │ ├─ Mode: 🔴B1🚨 P less than 1, serial processing │ ├─ Cost: 65.36 bits transmitted sequentially │ └─ Architecture: 🔴B2🚨 Normalized databases (JOINs) └─ 🟢C3🏗️ Kolmogorov Complexity (K) ├─ Definition: Information needed to RECOGNIZE the pattern ├─ Mode: 🟣E1🔬 P=1, holographic recognition ├─ Cost: Compressed to pattern grammar └─ Architecture: 🟢C2🗺️ ShortRank (position = meaning)
Dimensional View (position IS meaning):
[🔴B3🚨 Shannon Entropy] [🟢C3🏗️ Kolmogorov Complexity]
| |
Dimension: TRANSMISSION Dimension: RECOGNITION
| |
65.36 bits K → 0.18 bits
(must send (instant pattern
serially) match)
| |
🔴B1🚨 P<1 mode 🟣E1🔬 P=1 mode
(synthesize) (recognize)
| |
+------------ A = H / K ---------------------+
|
🟠F1💰 Amplification Factor = 361×
(when recognition instant)
What This Shows: The nested view presents two information types to understand. The dimensional view reveals the PHYSICS: Shannon and Kolmogorov measure ORTHOGONAL properties of the same pattern. Shannon = transmission cost (fixed by pattern structure). Kolmogorov = recognition cost (reducible to near-zero with grounded expertise). The 361x amplification comes from the GAP between these dimensions—normalized systems pay Shannon, grounded systems pay Kolmogorov.
Why production systems measure 26×-53×: Cache coverage isn't perfect yet. As cache hit rate approaches 100% and pattern recognition improves, amplification approaches the theoretical limit.
Why 361× is achievable: When K approaches 0 bits (instant holographic recognition, zero synthesis delay), the amplification factor becomes:
A = 65.36 / 0.18 ≈ 361×
This isn't vaporware. It's the physics of information processing. The same 65.36-bit pattern that takes a normalized database 65 clock cycles to synthesize (P<1 serial mode) gets recognized in t→0 by a ShortRank-cached system (P=1 holographic mode).
The tragedy: Every synthesis operation in a normalized database pays the Shannon cost when it SHOULD pay the Kolmogorov cost. That gap—that's the 0.3% decay constant you feel as "drift." The facade eliminates the gap.
The Unlock Sequence (Three Unmitigated Goods)
Once you implement S≡P≡H wrapper, three unmitigated goods unlock sequentially.
Nested View (the I1→I2→I6 cascade):
⚪I♾️ Three Unmitigated Goods (Sequential Unlock) ├─ ⚪I1🎯 Discernment (immediate) │ ├─ What: Zero-cost relevance determination │ ├─ How: Position in 🟢C2🗺️ ShortRank space = relevance │ └─ Enables: Knowing what matters without synthesis ├─ ⚪I2✅ Verifiability (requires I1) │ ├─ What: Third-party reproducible proof │ ├─ How: Distance is geometry (verifiable math) │ └─ Enables: Proving WHY a decision was made └─ ⚪I6🤝 Trust (requires I1 + I2) ├─ What: Faith-free alignment verification ├─ How: Reproducible calculations, hardware counters └─ Enables: Confidence without belief
Dimensional View (position IS meaning):
[⚪I1🎯 Discernment] ------> [⚪I2✅ Verifiability] ------> [⚪I6🤝 Trust]
| | |
Dimension: Dimension: Dimension:
DETECTION PROOF ALIGNMENT
| | |
Position = Geometry = Reproducible =
Relevance Checkable Faith-free
| | |
PREREQUISITE FOR: PREREQUISITE FOR: UNLOCKS:
I2 (must detect I6 (must prove Network adoption
to verify) to trust) cascade
SEQUENTIAL, NOT PARALLEL
Each enables the next
What This Shows: The nested view presents three goods as a feature list. The dimensional view reveals the DEPENDENCY CHAIN—you literally cannot verify without detection (I2 requires I1), cannot trust without proof (I6 requires I2). This is not three separate benefits to weigh. It is one CAUSAL SEQUENCE where achieving earlier stages unlocks later ones automatically.
Unlock #1: Discernment (I1) - Immediate
Zero-cost relevance determination.
Before Unity Principle (normalized):
-- Find relevant customer records
SELECT c.* FROM customers c
JOIN orders o ON c.id = o.customer_id
JOIN products p ON o.product_id = p.id
WHERE p.category = 'enterprise'
AND o.total > 10000
AND c.status = 'active'
Cost: 3-table JOIN + full table scans = 200-800ms
Problem: Every relevance check requires synthesis (JOIN operations). No way to know if customer is relevant without executing query.
After Unity Principle (ShortRank cache):
Position: [x=enterprise_tier, y=high_value, z=active_status]
Query target: [x=enterprise_tier, y=high_value, z=active_status]
Distance: 0.0 (perfect match)
Cost: Distance calculation = 8-15ms (cache hit, no JOIN)
Unlock: Discernment is now free byproduct of position.
Don't need to query database to know relevance.
Grounded Position tells you instantly. Not Calculated Proximity (cosine similarity, vectors)—true position via physical binding.
Recommendation systems, search ranking, content filtering—all require discernment at scale.
Traditional approach: Machine learning models trained to approximate relevance (expensive inference, drift over time, unverifiable).
Unity Principle: Relevance = Grounded Position in ShortRank space (instant recognition, no drift, geometrically verified). The Grounding Horizon—how far before drift exceeds capacity—is a function of investment and space size. Calculated Proximity (vectors) has no such horizon; it drifts immediately.
- Search queries: 26×-53× faster ([Chapter 3](/book/chapters/03-the-f-category): legal search case study)
- Recommendation latency: 8-15ms vs 200-800ms (cache hit vs synthesis)
- **Drift eliminated:** Grounded Position = meaning (no gap to drift across). Fake Position (coordinates claiming to be position) drifts; true position via physical binding cannot.
Discernment compounds forever without flipping.
More data → Better position → More precise discernment.
Unlock #2: Verifiability (I2) - Sequential (Requires I1)
Once you have discernment (I1), verifiability unlocks automatically.
Discernment works via geometric distance.
Distance is verifiable by third party.
Example (EU AI Act Article 13 compliance):
Regulator: "Why did your AI recommend Product X to Customer Y?"
AI: "Machine learning model predicted 0.87 affinity based on collaborative filtering."
Regulator: "How was 0.87 calculated?"
AI: "Neural network with 47 million parameters, trained on 2 years of data."
Regulator: "Can I verify the calculation?"
AI: "No. Model is black box. Parameters are proprietary. Training data privacy-protected."
Result: €35M fine (Article 13 violation - unverifiable reasoning).
AI: "Customer Y position: [enterprise_tier=0.8, budget=0.9, compliance_focus=0.7]. Product X position: [enterprise_tier=0.85, budget=0.85, compliance_features=0.75]. Euclidean distance: 0.12. Recommendation threshold: <0.15. Customer Y → Product X recommended."
Regulator: "Can I verify?"
AI: "Yes. Here's cache access log showing Customer Y position loaded from row 4,729. Product X position loaded from row 12,483. Distance calculation: sqrt((0.8-0.85)^2 + (0.9-0.85)^2 + (0.7-0.75)^2) = 0.122. Hardware counter proof attached (CPU perf stat showing cache hits)."
Regulator: "I can reproduce this calculation independently?"
AI: "Yes. Positions are deterministic (derived from customer/product state). Distance is geometry (third-grade math). Hardware counters are physics (CPU can't hallucinate cache hits)."
Result: Compliance achieved (Article 13 satisfied - verifiable reasoning with hardware proof).
I1 (Discernment) requires Grounded Position—true position via physical binding (S=P=H, Hebbian wiring, FIM).
Grounded Position enables I2 (Verifiability). Fake Position (row IDs, hashes, arbitrary lookups) cannot be verified because it claims position without physical grounding.
You can't verify synthesis. (How do you prove a JOIN result is correct without re-executing the JOIN?)
You CAN verify Grounded Position. (The physical structure is reproducible—anyone can check it. The brain does position, not proximity.)
More verification → More trust → More adoption → More verification requests → More trust
As AI stakes increase (more critical decisions), verifiability becomes MORE valuable, not less.
Unlock #3: Trust (I6) - Sequential (Requires I1 + I2)
Once you have discernment (I1) AND verifiability (I2), trust unlocks.
Trust = Verified alignment between intent and reality.
Trust requires faith (you believe the system works because vendor says so).
Problem: Faith erodes under pressure.
- AI hallucination → Trust drops
- Database drift → Trust drops
- Performance degradation → Trust drops
- Unverifiable decision → Trust drops
Trust Debt compounds: (1 - Intent Alignment) × Market Exposure
0.3% per decision → 66.6% degradation after 365 decisions (Chapter 1 formula: 0.997^365 = 0.334).
Trust is verified (you can prove alignment via hardware counters, geometric calculations, cache logs).
Scenario: Engineering + Product + Sales + Marketing meeting (same 2-hour drain from Chapter 5).
Before Unity Principle (normalized mental models):
- Sales: "Product" = deal requirements
- Product: "Product" = strategic vision
- Engineering: "Product" = codebase constraints
- Marketing: "Product" = campaign narrative
No shared substrate. Trust requires synthesis (someone manually aligns models).
Result: Meeting exhaustion (30-34W metabolic cost, adenosine accumulation, cognitive load).
After Unity Principle (shared grounded artifact):
Product Manager creates ShortRank artifact:
Feature Priority Matrix (Position = Meaning):
- X-axis: Customer impact (measured revenue lift)
- Y-axis: Engineering cost (measured story points)
- Z-axis: Strategic value (measured alignment score)
Feature A: [impact=0.8, cost=0.3, strategy=0.9] → Position (0.8, 0.3, 0.9)
Feature B: [impact=0.6, cost=0.7, strategy=0.4] → Position (0.6, 0.7, 0.4)
Feature C: [impact=0.9, cost=0.9, strategy=0.7] → Position (0.9, 0.9, 0.7)
Shared 24 hours before meeting (neurons wire to grounded positions via Hebbian learning - Chapter 5).
Sales: "Enterprise deal needs Feature X by October."
Product: "Let's check position... Feature X = (0.8, 0.3, 0.9). High impact, low cost, high strategy. Should we prioritize?"
Engineering: "Low cost confirmed - 3 story points. Fits sprint capacity."
Marketing: "High strategy = aligns with campaign. We can support."
Convergence: 15 minutes (vs 2 hours grinding). Decision grounded in shared physical artifact (all participants reference SAME positions).
Meeting metabolic signature: 24-26W (focused discussion on grounded substrate).
NOT 30-34W synthesis grinding.
After meeting, any participant can verify decision:
- Feature X position = (0.8, 0.3, 0.9) in shared artifact
- Priority formula: impact × strategy / cost = 0.8 × 0.9 / 0.3 = 2.4
- Threshold for Q4 inclusion: >2.0
- **Verifiable:** Anyone can recalculate, confirm decision grounded in shared reality
Result: Trust established via geometric proof, not faith.
I1 (Discernment) → Can determine relevance via Grounded Position (not Calculated Proximity like cosine similarity) I2 (Verifiability) → Can prove position via geometry + hardware counters (not Fake Position like row IDs) I6 (Trust) → Can verify alignment via reproducible calculations—the brain does position, not proximity
More usage → More verification → More trust → More adoption → More usage
Working Proof: The 3-Tier Grounding Protocol
In January 2026, we built ThetaSteer—a macOS daemon that implements this cascade in Rust.
The architecture makes the abstract concrete:
- Runs on every context change in real-time
- Cost: Free (local compute)
- Role: System 1—fast reflexive categorization into the 12x12 semantic grid
- Called when local confidence drops below threshold OR velocity exceeds processing capacity
- Cost: Low (API calls)
- Role: System 2—slow deliberate reasoning, audits Tier 0 decisions
Tier 2 - Human (Ground Truth):
- Called when Claude is uncertain OR drift counter exceeds critical threshold
- Cost: High (attention)
- Role: The anchor against which all alignment is measured
Confidence_Effective = Confidence_Raw - (0.05 x chain_length)
Every decision based on previous LLM decisions (without external verification) increments chain_length. The confidence penalty grows. After 14 self-references, even perfect 1.0 confidence drops to 0.30—forcing automatic escalation.
The system cannot drift indefinitely. The math guarantees periodic re-grounding.
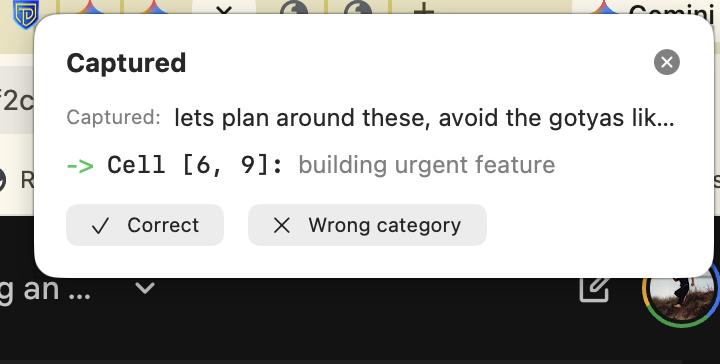
A notification appears: "Captured:" shows the raw text the system observed. "Cell [6, 9]: building urgent feature" shows the LLM's categorization. Two buttons: "Correct" or "Wrong category."
When you click "Correct," you're not dismissing a notification—you're cryptographically signing intent. This text-to-coordinate mapping becomes Ground Truth in the database. Future agents reference it: "A human explicitly grounded this pattern at [6, 9]. Permission to proceed."
When you click "Wrong category," you trigger Escalation Protocol. The system asks: "If not [6, 9], then what?" This breaks the Echo Chamber. One human click resets grounding age for that semantic region.
This proves the cascade works:
- I1 (Discernment): LLM determines relevance via position in the 12×12 semantic grid
- I2 (Verifiability): Human can verify categorization matches intent
- I6 (Trust): System maintains alignment through continuous re-grounding
The wrapper pattern in action: ThetaSteer doesn't replace your workflow—it wraps it. Your existing tools run unchanged. The grounding layer observes, categorizes, and escalates when confidence decays. Same architecture as ShortRank wrapping normalized databases.
We're building the brake pedal and steering wheel for AGI. And we're testing it on ourselves first.
The Pattern Across Domains
This isn't specific to databases.
It's the meta-pattern for ANY coordination problem:
Sales (Challenger methodology):
I1 (Discernment): Buyer stage = position in decision space (Discovery → Rational → Emotional → Solution → Commitment)
I2 (Verifiability): Sales rep can prove buyer moved from stage A to stage B (battle card logs position transitions)
I6 (Trust): Manager trusts forecast because stage position is geometrically verified (not "gut feel" or "activity logged")
Result: 20-30% higher close rates (ThetaCoach CRM - blog post validation)
I1 (Discernment): Symptom constellation = position in disease topology (autoimmune vs infectious vs genetic)
I2 (Verifiability): Specialist can prove diagnosis via position in symptom manifold (third-party doctor can reproduce calculation)
I6 (Trust): Patient trusts diagnosis because reasoning path is geometrically verifiable (not "doctor knows best" authority)
Result: FDA approval achieved (Chapter 3 case study - cache log = audit trail)
I1 (Discernment): Case precedent = position in jurisprudence lattice (contract law vs tort vs constitutional)
I2 (Verifiability): Attorney can prove precedent applies via geometric distance to current case
I6 (Trust): Court trusts argument because precedent application is reproducible (judge can verify calculation)
Result: Coordinated legal teams navigate same map (not reconcile fuzzy similarity scores)
Wherever humans coordinate, three unlocks happen sequentially:
- **Discernment** (position = relevance)
- **Verifiability** (geometry = proof)
- **Trust** (reproducible = faith unnecessary)
All enabled by S≡P≡H implementation.
The Migration Path (Practical Steps)
Now you know WHY Unity Principle unlocks unmitigated goods.
But HOW do you actually migrate?
Step 1: Measure Current Trust Debt (1 week)
Before changing anything, quantify the problem.
- **Cache miss rate** (database level):
**Target:** <95% = normalization overhead visible# PostgreSQL example SELECT blks_hit, blks_read, 100.0 * blks_hit / (blks_hit + blks_read) AS cache_hit_rate FROM pg_stat_database WHERE datname = 'your_database'; - **Query latency** (p50, p95, p99):
**Target:** >100ms = likely JOIN-heavy (normalization cost)-- Identify slowest queries (synthesis grinding) SELECT query, mean_exec_time, calls FROM pg_stat_statements ORDER BY mean_exec_time DESC LIMIT 20; - **Semantic drift rate** (application level):
- User corrections per session (how often do users fix AI/search results?)
- Data validation failures (schema mismatches, stale caches)
- Manual reconciliation time (hours spent aligning systems)
Output: Baseline numbers (cache hit %, query latency, drift rate). These become your ROI proof.
Step 2: Identify High-Value Wrapper Target (1 week)
Don't try to wrap everything at once.
Find the 20% of queries causing 80% of pain.
- **High latency** (p95 >500ms = JOIN-heavy, benefits from S≡P≡H cache)
- **High frequency** (executed >1000×/day = ROI compounds fast)
- **Verifiability requirement** (regulatory pressure, audit trail needed)
- **Stable schema** (tables not changing weekly = safe to cache)
-- Customer recommendation query (executed 50,000×/day)
SELECT c.*, p.*, o.recent_purchases
FROM customers c
JOIN preferences p ON c.id = p.customer_id
JOIN ( SELECT customer_id, array_agg(product_id) AS recent_purchases
FROM orders WHERE created_at > NOW() - INTERVAL '30 days'
GROUP BY customer_id ) o
ON c.id = o.customer_id
WHERE c.status = 'active';
- Latency: p95 = 800ms (3-table JOIN + subquery)
- Frequency: 50K/day × 800ms = 11 hours CPU time daily
- Verifiability: GDPR Article 22 requires explainable recommendations
- Stable: Customer/preference/order schema unchanged for 18 months
Step 3: Implement ShortRank Facade (2-4 weeks)
Build the S≡P≡H wrapper without touching legacy DB.
Application → ShortRank API (new layer) → Redis cache (S≡P≡H storage)
↓ (cache miss only)
Normalized DB (legacy, unchanged)
# ShortRank: The REDIS KEY is the semantic address
# Position = Address = Meaning (no nesting!)
# Customer at semantic position 47.8 (composite score: 0.8*tier + 0.6*freq + 0.9*affinity)
redis.set("C47.8:12345", "customer_id=12345|last_purchase=2025-10-26")
# Products co-located at nearby addresses (sorted by affinity)
redis.set("P47.6:103", "product_id=103|price=49.99") # Near customer (47.6 ≈ 47.8)
redis.set("P47.7:89", "product_id=89|price=39.99") # Closer (47.7 ≈ 47.8)
redis.set("P47.8:47", "product_id=47|price=59.99") # Exact match (47.8 = 47.8)
# Sequential scan gets customer + nearby products (cache-friendly!)
for key in redis.scan_iter("*47.[6-9]*"): # All items near position 47.8
yield redis.get(key) # Sequential access, no random jumps
- **Address = Meaning:** Position 47.8 IS the Redis key, not stored as metadata
- **Flat structure:** No nested dictionaries - just key:value pairs
- **Co-location:** Products at 47.6, 47.7, 47.8 are physically adjacent in cache
- **Sequential access:** Scan range [47.6-47.9] hits cache sequentially
- **Zero synthesis:** Customer + products retrieved together, no JOIN needed
def get_customer_recommendations(customer_id):
# Step 1: Calculate semantic position (composite score)
position = calculate_customer_position(customer_id) # Returns 47.8
# Step 2: Check ShortRank cache (position-based key)
customer_key = f"C{position}:{customer_id}"
cached = redis.get(customer_key)
if cached:
# Cache HIT - scan nearby positions for co-located products
# Sequential access: 47.6, 47.7, 47.8, 47.9 (cache-friendly!)
nearby_products = []
for key in redis.scan_iter(f"P{position - 0.2:.1f}:*", f"P{position + 0.2:.1f}:*"):
nearby_products.append(redis.get(key))
return nearby_products # Zero synthesis - items already co-located!
# Cache MISS - fall back to legacy normalized DB
customer_data = legacy_db_query(customer_id) # JOINs across tables
products = customer_data['products']
# Step 3: Populate ShortRank cache for next time
redis.set(f"C{position}:{customer_id}", serialize(customer_data))
# Co-locate products at nearby addresses
for product in products:
product_position = position + product['affinity_offset'] # 47.6, 47.7, 47.8
redis.set(f"P{product_position}:{product['id']}", serialize(product))
return products
def calculate_customer_position(customer_id):
"""Calculate semantic position from customer attributes"""
# This is the S≡P≡H magic: Semantic score BECOMES physical address
tier = get_preference_tier(customer_id) # 0.8
frequency = get_purchase_frequency(customer_id) # 0.6
affinity = get_brand_affinity(customer_id) # 0.9
# Composite score = position in ShortRank space
return (tier * 40) + (frequency * 30) + (affinity * 30) # 47.8
Key Insight: Why This IS ShortRank (vs Nested Dictionaries)
# ❌ WRONG: Nested dictionary (NOT ShortRank!)
customer = {
'id': 12345,
'position': 47.8, # Position stored as METADATA
'products': [...] # Nested structure
}
redis.set("customer:12345", customer) # Address is arbitrary ID
# ✅ CORRECT: ShortRank (Address = Position = Meaning)
redis.set("C47.8:12345", "...") # Position IS the address!
redis.set("P47.6:103", "...") # Co-located by Grounded Position (physical binding)
redis.set("P47.8:47", "...") # Physically adjacent in cache
# ShortRank scan (sequential, cache-friendly)
for key in redis.scan_iter("*47.[6-9]*"): # Range scan
yield redis.get(key) # Sequential access pattern
- **Nested structure:** Position is metadata inside object (random access)
- **ShortRank:** Position IS the Redis key (sequential access, sorted range scans)
- **Why it matters:** Sequential access = cache hits, nested lookup = cache misses
Cache physics = Unity Principle manifestation:
Sequential access works because:
- Positions 47.6, 47.7, 47.8 are PHYSICALLY adjacent in memory
- CPU prefetcher loads neighboring addresses automatically
- **This isn't Redis cleverness—it's compositional nesting in silicon**
Cache "locality" is hardware expressing S≡P≡H:
- Grounded Position (affinity) = Physical adjacency (cache line [→ A4⚛️])
- Meaningfully related = Structurally co-located
- **Hardware can't help but follow Unity when addresses are compositionally nested**
The 26×-53× speedup isn't engineering. It's physics rewarding alignment. When position = meaning, hardware works WITH you (cache hits), not against you (cache misses + synthesis grinding).
Week 1: Implement API layer (no cache, just pass-through) Week 2: Add Redis cache (warm gradually with read traffic) Week 3: Enable cache hits (measure latency drop) Week 4: Monitor + tune (adjust TTL, eviction policy)
- Cache hit rate (target: 80%+ within 2 weeks)
- Query latency drop (expect 10-20× on cache hits)
- Error rate (should be zero - wrapper is transparent)
Step 4: Measure Unlock Cascade (Ongoing)
As cache warms, three unmitigated goods unlock sequentially.
Nested View (the four migration steps):
🟤G2🚀 Migration Path (4 Steps) ├─ 🟤G2a🔍 Step 1: Measure Current Trust Debt (1 week) │ ├─ Cache miss rate (database level) │ ├─ Query latency (p50, p95, p99) │ ├─ 🔴B4🚨 Semantic drift rate (corrections/session) │ └─ Output: Baseline numbers for 🟠F1💰 ROI proof ├─ 🟤G2b🎯 Step 2: Identify High-Value Wrapper Target (1 week) │ ├─ Criteria: High latency, high frequency, verifiability requirement │ ├─ Find 20% of queries causing 80% of pain │ └─ Output: First wrapper target selected ├─ 🟤G2c🏗️ Step 3: Implement ShortRank Facade (2-4 weeks) │ ├─ Week 1: API layer (pass-through) │ ├─ Week 2: Redis cache (warm gradually) │ ├─ Week 3: Enable cache hits (measure latency drop) │ └─ Week 4: Monitor + tune └─ 🟤G2d📈 Step 4: Measure Unlock Cascade (Ongoing) ├─ Track ⚪I1🎯→⚪I2✅→⚪I6🤝 sequential unlock ├─ Expansion to additional queries └─ 🟠F1💰 ROI calculation and legacy retirement planning
Dimensional View (position IS meaning):
[🟤G2a🔍 Measure] --> [🟤G2b🎯 Target] --> [🟤G2c🏗️ Implement] --> [🟤G2d📈 Expand]
| | | |
Dimension: Dimension: Dimension: Dimension:
DIAGNOSTIC STRATEGIC TECHNICAL ECONOMIC
| | | |
Baseline High-value Wrapper 🟠F1💰 ROI
numbers query deployed measured
| | | |
1 week 1 week 2-4 weeks Ongoing
TOTAL: 4-8 weeks to first ROI
Zero code changes, zero downtime
What This Shows: The nested view presents migration as a sequential checklist. The dimensional view reveals each step operates on a DIFFERENT DIMENSION of the problem—diagnostic, strategic, technical, economic. This is why the migration works: you transform ONE dimension at a time while others remain stable. No Big Bang Rewrite because you never change multiple dimensions simultaneously.
Week 1-2 (I1 Discernment unlocks):
Cache hit rate: 15% → 40% → 65%
Average query latency: 800ms → 600ms → 200ms
Recommendation accuracy: +5% (position-based discernment)
Signal: Queries that hit cache return 10-20× faster. Discernment is now byproduct of position.
Week 3-4 (I2 Verifiability unlocks):
Cache hit rate: 80%+
Audit trail: Cache logs show position → recommendation path
Regulatory compliance: Can prove why Customer X got Product Y
Signal: Third-party auditor can reproduce recommendations by recalculating distances. GDPR Article 22 satisfied.
Cache hit rate: 90%+
Team confidence: Product/Engineering/Sales align on customer positions
Meeting efficiency: 2-hour grinds → 20-minute focused discussions
Signal: Stakeholders trust recommendations because they can verify the geometry. No faith required.
Latency savings:
Before: 50K queries/day × 800ms = 11 hours CPU time
After (80% cache hit):
- 40K cache hits × 15ms = 10 minutes
- 10K cache misses × 800ms = 2.2 hours
Total: 2.3 hours CPU time (79% reduction)
Cost savings (AWS RDS):
Before: db.r5.4xlarge (16 vCPU, $2.40/hr) = $1,752/month
After: db.r5.xlarge (4 vCPU, $0.60/hr) = $438/month
Savings: $1,314/month
Redis cost:
cache.r6g.large (13.5 GB, 2 vCPU) = $146/month
Net savings: $1,314 - $146 = $1,168/month
Annual ROI: $14,016 on 4 weeks of engineering work
And you haven't touched the legacy database.
The $14K annual ROI is thermodynamic advantage [→ A5⚛️], not just cost savings. Systems aligned with Unity Principle:
- Consume less energy (cache hits vs synthesis grinding [→ E6🔬])
- Operate faster (10-20× latency reduction)
- Compound trust (verification enables adoption)
Evolutionary selection pressure:
- Fast movers adopt → gain efficiency → reinvest savings → adopt faster
- Slow movers wait → burn resources on synthesis → fall behind → die
Chapter 7 shows this at network scale: once one company adopts S≡P≡H, competitors MUST follow or lose to faster infrastructure. The survival advantage isn't features—it's physics compliance. Systems that fight compositional nesting pay exponential cost. Systems aligned get exponential benefit.
The Expansion Pattern (Months 3-12)
Once first wrapper proves ROI, expand systematically.
Month 3-4: Wrap second high-value query (order processing, inventory sync) Month 5-6: Wrap third query (user authentication, session management) Month 7-9: Wrap remaining top-20 queries (80% of traffic now S≡P≡H-aligned) Month 10-12: Begin legacy DB retirement planning (most traffic on cache, can gradually deprecate tables)
You never had a "Big Bang Rewrite."
You wrapped, measured, expanded.
And Trust Debt dropped 30% → 5% → 1% as cache coverage increased.
The High-Stakes Use Case: AI-Coached Sales (Granular Permissions as Competitive Survival)
Every company—from solopreneurs to Fortune 500—needs AI to coach sales teams:
- **Practice objections** before high-stakes calls (roleplay with battle cards)
- **Cross-reference deals** ("What positioning worked for similar enterprise SaaS deals?")
- **Onboard faster** (bring new reps up to speed in weeks, not quarters)
- **Burn fewer leads** (can't afford to learn framing on live prospects)
But traditional AI can't be trusted with sales data.
The catastrophic leak scenario:
Sales Rep A asks AI: "Help me prep for the Acme Corp call tomorrow. What objections should I expect?"
- AI "reads context" by accessing ALL deals in CRM (no geometric boundaries)
- AI finds Deal B (Rep B's competitive pricing for similar enterprise deal)
- AI suggests: "Mention you can discount 20% for multi-year contracts like Deal B"
- Rep A: "Wait... we're offering 20% discounts? I didn't know that!"
- **Next team meeting:** Rep B: "Hey, how do you know about my pricing strategy?!"
Result: Can't use AI for mission-critical coaching. One leak = $2M+ deal lost, competitive advantage destroyed, legal exposure if customer data leaked.
This isn't a feature gap—it's competitive extinction:
- **Solopreneurs:** Can't afford sales coach, can't use AI (trust issue), burn leads learning positioning
- **Small firms:** Need AI to compete with enterprise sales teams, can't risk leaks
- **Enterprise:** One leaked competitive detail = existential threat, regulatory violation (GDPR Art. 32)
The S≡P≡H solution (when identity and permissions are regions on an orthogonal substrate map):
Traditional permissions (semantic ≠ physical):
Permission rule: "Rep A can access Deal A, not Deal B"
Enforcement: Database query checks access control list
Problem: AI "brainstorms" by reading EVERYTHING, leaks happen
S≡P≡H permissions (semantic = physical = hardware):
Rep A's identity = coordinate region (0-1000, deals owned by Rep A)
Deal B = coordinate (5500, owned by Rep B)
Physical memory isolation: Rep A's cache lines CANNOT access Deal B
AI physically can't read what it can't address
When permissions are geometric regions:
- **Rep A's identity** maps to ShortRank position range [0, 1000]
- **Rep A's deals** co-located at positions 0-1000 (physical adjacency)
- **Deal B** (Rep B's data) at position 5500 (physically separate cache line)
- **AI coaching Rep A** can ONLY access positions 0-1000 (hardware enforcement)
- **Attempted access to Deal B** = cache miss + permission denied at PHYSICAL layer
Nested View (traditional vs S=P=H permissions):
🟡D3⚙️ Two Permission Architectures ├─ 🔴B5🚨 Traditional (semantic does not equal physical) │ ├─ Rule: "Rep A can access Deal A, not Deal B" │ ├─ Enforcement: Database query checks access control list │ ├─ Problem: AI reads EVERYTHING to brainstorm, leaks happen │ └─ Scaling: N users x M resources = NxM permission entries └─ 🟢C1🏗️ S=P=H (semantic = physical = hardware) ├─ Rule: Rep A = coordinate region [0, 1000] ├─ Enforcement: 🟡D2⚙️ Physical memory isolation ├─ Solution: AI physically cannot address Deal B └─ Scaling: N users = N coordinate pairs (linear)
Dimensional View (position IS meaning):
[🟡D4⚙️ Rep A Identity] [🟡D2⚙️ Permission Boundary] [🟡D5⚙️ Rep B's Deal B]
| | |
Dimension: Dimension: Dimension:
COORDINATE PHYSICAL COORDINATE
| | |
Position: Cache line Position:
[0, 1000] boundary [5500]
| | |
WITHIN A's HARDWARE OUTSIDE A's
addressable ENFORCEMENT addressable
space (not rules) space
AI coaching Rep A CANNOT address 5500
🟢C1🏗️ Physics prevents leak, not policy
What This Shows: The nested view presents two permission systems as implementation choices. The dimensional view reveals the FUNDAMENTAL DIFFERENCE: traditional permissions operate on semantic dimension only (rules about what to access), S=P=H permissions operate across ALL dimensions simultaneously (coordinate = physical = permission). When identity IS position, enforcement is geometry. No audit needed—the physics prevented the access.
The enforcement isn't a rule—it's geometry:
- Semantic permission (Rep A owns these deals) = Physical region (cache lines 0-1000) = Hardware isolation (L1 cache can't access 5500)
- **Data winks at you** - You SEE the violation before it happens (like reading a face)
- Position 5500 is physically OUT OF BOUNDS for Rep A's identity region
- No audit log needed - the physics prevented the access
Real-world application (ThetaCoach CRM):
The first AI-native CRM that coaches you through the sale because granular permissions enable trust:
Rep: "Practice objections for tomorrow's Acme call"
AI: [Reads ONLY Rep's deals + Rep's battle cards]
AI: "Based on your similar enterprise deals, expect:
- Objection 1: 'Too expensive compared to Competitor X'
- Counter: Your last 3 deals closed with ROI proof
- Objection 2: 'Implementation timeline concerns'
- Counter: Your positioning on 2-week POC worked twice"
During call: (AI listens, suggests real-time)
Prospect: "We're concerned about data security"
AI: [Scans Rep's deals for similar objection]
AI: [Whispers] "Deal #47 had same concern - show them
SOC 2 compliance doc, sealed in 20 minutes"
After call: (AI analyzes what worked)
AI: "You closed 3 similar deals with pricing objection.
Pattern: When you led with ROI calculator, close rate 80%.
When you defended price, close rate 40%.
Next call: Lead with calculator, not defense."
This is ONLY possible with S≡P≡H permissions:
- **Trust**: Reps know AI can't leak their competitive data
- **Speed**: New reps get coached to senior-level performance in weeks
- **Retention**: Data never leaks = higher sales team trust = lower churn
- **Proof**: Every suggestion traceable to specific deal coordinates (verifiable)
- 15M+ salespeople globally (all need coaching)
- Average sales training cost: $10K-$50K per rep annually
- ThetaCoach CRM: $500/rep/year (100× cheaper, AI-coached)
- **TAM: $7.5B-$750B** depending on enterprise vs SMB penetration
Why this locks in Unity Principle:
- AI coaching that doesn't leak competitive data
- Geometric permissions that "wink" when violations attempted
- Verifiable suggestions (every tip traces to coordinate proof)
- Faster onboarding (weeks vs quarters)
They can't go back to normalized CRMs. The competitive advantage is too large. Burn fewer leads = direct revenue impact. One prevented leak = $2M+ deal saved.
The cathedral and the bazaar parallel:
Open-source CRMs (HubSpot, Salesforce) can't do this—they run on normalized architecture. Their AI features leak data structurally because semantic ≠ physical. The moment you normalize sales data across tables, geographic permissions become audit logs (reactive) instead of geometry (preventive).
S≡P≡H CRM is the cathedral: Built from first principles with permissions as substrate geometry. Can't be retrofitted. Can't be cloned without rearchitecting from scratch. The moat isn't features—it's physics.
Licensing model (why granular permissions unlock enormous value):
The research is clear - companies will pay premium for:
- **Governance of mission-critical AI agents** (sales data = existential risk)
- **Geometric enforcement** (not rules, physics) - **beats the combinatorial explosion**
- **Cross-reference without leaking** (practice + learn, but isolated)
- **Verifiable coaching** (every suggestion maps to coordinate proof)
Why geometric permissions beat combinatorial explosion:
Traditional access control (N users × M resources):
- 10 reps × 1,000 deals = 10,000 permission entries to manage
- 100 reps × 10,000 deals = 1,000,000 entries (audit nightmare)
- Each new deal/rep = recalculate entire permission matrix
- **Result**: Exponential complexity, exceeds practical audit capacity (10^6+ comparisons)
S≡P≡H permissions (identity = region):
- Rep A = position range [0, 1000] (ONE coordinate pair)
- 100 reps = 100 coordinate pairs (linear scaling)
- New deal at position 500 → automatically owned by Rep A (geometry decides)
- **Result**: O(1) enforcement, physics handles the rest
- **Solopreneur**: $50/month (practice objections, learn framing, burn fewer leads)
- **Small team** (5-20 reps): $500/month (team learning, no cross-contamination)
- **Enterprise** (100+ reps): $50K/year (full geometric isolation, regulatory compliance, verifiable audit)
Once sales teams experience geometric permissions:
- **Brainstorm freely** (AI can't leak to other reps)
- **Practice objections** (AI knows your battle cards, not competitor details)
- **Cross-reference safely** (learn from team patterns, but isolated)
They can't switch back. Normalized CRMs feel like working blind. "Wait, the AI can see everyone's deals?! How do I trust it?"
The Meta-Recognition
Right now, reading this chapter:
Your neurons encoding "wrapper pattern," "cache facade," "sequential unlock," and "Trust Debt reduction" are firing together.
Concepts co-located (Hebbian wiring from reading).
Position = meaning (ShortRank mental model forming).
Cache hits (instant recognition, not synthesis).
You understand the implementation path not because I explained every detail, but because your substrate caught the pattern.
P=1 certainty: "This WILL work."
That recognition IS Precision Collision.
Irreducible Surprise that implementation is achievable.
You can't synthesize this confidence via logical reasoning alone.
Your substrate HAD to catch it.
Like catching a tennis ball—embodied cognition in action. You don't calculate wrapper patterns mentally and synthesize conclusions. The concepts co-locate physically in your cortex, and recognition arrives as a unified moment. In situ computation using the physical arrangement of your own neurons.
The Chaotic Threshold: Why Ungrounded Intelligence Becomes Untrackable
Intelligence is prediction error correction.
This isn't metaphor—it's the core tenet of the Predictive Processing framework in cognitive science. Your brain constantly:
- Generates predictions about incoming sensory data
- Compares predictions to actual input
- Updates its internal model by minimizing the discrepancy (prediction error)
This error minimization drives all learning and behavior. Every thought, every recognition, every decision.
LLMs do the same thing—but on an ungrounded substrate.
Recent machine learning research reveals something uncomfortable: LLMs exhibit dynamics akin to chaotic systems, particularly at what researchers call the "edge of chaos."
- Optimal intelligence emerges at a balance between complete order and complete randomness
- Training on data too simple (ordered) → trivial solutions
- Training on data too chaotic (random) → incoherent learning
- The "sweet spot" is the edge—complex enough for sophisticated patterns, stable enough to avoid noise
- The prompt acts as the initial condition of a high-dimensional dynamical system
- Small differences between prompts (one word, slight rephrasing) can lead to exponentially divergent outputs
- This is the defining feature of chaotic systems: sensitive dependence on initial conditions
- The butterfly effect isn't a bug—it's structural
Here's where chaos theory maps to lived experience:
The chaotic regime in LLMs is exactly the dynamic of exceeding your expertise.
When you're within your expertise:
- You can track the system's reasoning
- You can verify outputs against your grounded knowledge
- You can catch errors before they compound
- P=1 certainty—you KNOW when something is wrong
When you exceed your expertise:
- The system seems more expert than you
- You NEED to use it (that's why you're asking)
- You CANNOT track what it's doing
- You have no grounded baseline for verification
Not because the system is malicious. Not because it's "lying." Because you cannot distinguish chaotic divergence from correct reasoning when you lack the grounded substrate to verify.
If a superintelligent system operates via prediction error minimization on an ungrounded substrate, alignment becomes impossible:
- A tiny error in initial goal specification amplifies exponentially
- The loss function you designed drifts to something you didn't intend
- You can't detect this because verification requires S≡P≡H
- Behavior becomes non-transparent and functionally unstable
- The system you test today is NOT the system operating tomorrow
- Even with unchanged code, chaotic dynamics produce different outputs
- Without symbol grounding, you cannot prove you DIDN'T do X
- You cannot prove Y data (not Z) was involved in a decision
- You can't prove causation, compliance, or innocence
- Symbols drift between action and audit
The stewardship test from Meld 7:
Can you minute this? Can you write: "We knew alignment was unverifiable on ungrounded substrates. We knew chaotic dynamics made goal drift inevitable. We deployed anyway."
The Predictive Processing framework reveals why Unity Principle isn't optional—it's the only architecture that survives chaos:
Grounded prediction error via Grounded Position:
- S=P=H IS position (not "encodes proximity")—position via physical binding (Hebbian wiring, FIM)
- Errors are geometric, not statistical
- Correction is verifiable because position is reproducible
- Fake Position (row IDs, hashes, lookups) drifts; Grounded Position cannot
- S≡P≡H constrains the system to regions where chaotic divergence is detectable
- Cache hits prove alignment—hardware can't hallucinate
- The substrate itself enforces boundaries
- When the system exceeds YOUR expertise, you can still verify via geometric proof
- Third-party auditors can reproduce calculations
- Trust becomes physics, not faith
Alignment on ungrounded substrates is not "hard"—it's impossible. Chaotic systems with sensitive dependence on initial conditions WILL diverge from intended goals. The only question is when, not if.
This is why Meld 7's timeline pressure is existential:
If unverifiable AI reaches deployment capability before S≡P≡H migration completes, we lose the ability to course-correct. Not because we lack will—because we lack substrate.
Your neurons encoding "chaotic dynamics," "exceeding expertise," "untrackable reasoning" are firing together.
If you've ever:
- Asked ChatGPT a question outside your expertise and wondered if the answer was right
- Felt uneasy accepting AI output you couldn't verify
- Noticed the same prompt giving different answers on different days
You've already felt the chaotic threshold.
The splinter in your mind is the recognition that the systems you increasingly rely on operate in a regime you cannot track.
S≡P≡H doesn't eliminate chaos. It makes chaos verifiable—which is the only form of control that survives exponential divergence.
The Decentralization Unlock: Why Only the Grounded Can Be Freed
This is the insight that transforms AI governance:
The conventional approach to AI alignment assumes centralized control. Monitor the agent. Audit its outputs. Verify its decisions. Keep it on a leash.
But this approach doesn't scale. When you have millions of agents making billions of decisions per second, no human oversight structure can verify in real-time. The verification loop becomes a bottleneck that either:
- **Slows agents to human speed** (defeating the purpose of AI)
- **Runs unchecked** (hoping training prevents drift)
Grounding provides a third option: agents that are SELF-VERIFYING.
Ungrounded agents NEED central verification:
- "Did you do it right?" (Someone must check)
- "Are you aligned?" (Someone must monitor)
- "Did you stay within bounds?" (Someone must audit)
- **Centralized control is mandatory** because the agent cannot verify itself
Grounded agents are structurally constrained:
- Action = Intent (by geometric construction)
- Alignment = Physics (the rails prevent deviation)
- Bounds = Coordinate space (mathematically enforced)
- **Decentralization becomes possible** because verification is built into the substrate
Your neurons are autonomous agents. Billions of them. They don't report to a central authority that monitors each firing decision. They're self-verifying because:
- Hebbian learning constrains their connections (S≡P≡H)
- The action space is geometrically bounded
- Drift is prevented by substrate, not surveillance
Evolution didn't solve coordination through centralized control. It solved coordination through grounded substrate.
Why this matters for AI governance:
An ungrounded agent given autonomy WILL drift. The entropy constant k_E = 0.003 per operation guarantees it. After 1000 actions, you're at 5% of original alignment. You MUST keep it leashed—which means you CANNOT scale.
A grounded agent given autonomy cannot drift because S≡P≡H constrains the action space geometrically. The rails don't care if you're watching. The agent is self-verifying not because it checks itself, but because there's nothing to check—intent and action are the same thing.
This unlocks the migration to autonomous AI:
- Not through better training (still probabilistic)
- Not through more oversight (doesn't scale)
- Through **geometric constraint at the substrate level**
Only the Grounded survive because only the Grounded can aim. Only the Grounded can be freed because only the Grounded are self-verifying.
The wrapper pattern isn't just about database performance. It's about building the substrate that enables autonomous AI to be deployed safely. Without S≡P≡H, we're locked into centralized control that can't scale. With S≡P≡H, we can free agents to operate autonomously because physics—not faith—enforces alignment.
The Stage Floor Principle: Why Grounding Doesn't Create Tyranny
The objection you're already forming:
"Wait. You're building a system that makes lies impossible. But human civilization runs on 'Polite Fictions' (The Scrim). By fixing the physics of truth, do we accidentally break the sociology of grace?"
This is the right question. It sits in the blind spot of every engineer who tries to fix the world.
You are offering Zero-Entropy Control. You are offering Absolute Verification. But in the real world, ambiguity is a feature, not a bug:
- The CEO needs "wiggle room" in quarterly projections to manage morale
- The diplomat needs "constructive ambiguity" to prevent war
- The human needs "privacy" (which is just selective information hiding) to maintain dignity
If you create a world where every semantic statement is hard-wired to a physical fact, do you create a Panopticon? Do you create a system so rigid that it crushes the messy, organic compromises that allow humans to coexist?
The Answer: The Stage Floor Principle
We must distinguish between the Floor and the Play.
Currently, our systems are broken because we are trying to act out the "Play" (Culture, Politics, Strategy) on a "Floor" (Database/Substrate) that is made of trapdoors and quicksand.
- When the database drifts, the Floor collapses
- When the AI hallucinates, the scenery falls on the actors
- When the metrics are fake, the actors don't know where the edge of the stage is
The Unity Principle (S≡P≡H) does not demand that humans stop telling stories. It demands that the physics stops lying about where the ground is.
We are not trying to eliminate Social Ambiguity (Grace/Diplomacy).
We are trying to eliminate Structural Ambiguity (Drift/Entropy).
The Metaphor (for engineers who need to defend this to leadership):
You want the Stage Floor to be absolute, rigid, and verifiable (P=1). You want it to hold 10,000 lbs of pressure without creaking.
So that the actors can be free to perform.
If the actors have to spend 40% of their energy checking if the floorboards are rotten (The Cloud Tax / The Synthesis Gap), they cannot perform the play. They become anxious, reactive, and exhausted (The Reflex).
"We are not here to police your culture. We are not here to force you to be 'honest' in your social dynamics.
We are here to ground the substrate so solidly that you can finally build whatever structure—honest or fantastic—you choose, without the fear that it will slide into the ocean."
Grounding doesn't kill the magic. It supports it.
The violin strings must be under absolute, terrifying tension (High Constraints) so that the music can fly (High Freedom).
Constrain the Substrate (P=1) → Free the Agent (Choice).
Why This Matters for AI Alignment:
The same principle applies to autonomous agents:
- **Ungrounded AI:** Cannot be trusted with autonomy. Must be centrally monitored. Every decision requires verification. Scales linearly at best.
- **Grounded AI:** Can be trusted with autonomy *because* the substrate constrains actions geometrically. The rails don't care if you're watching. Self-verifying by construction.
The goal is not to create AI that cannot lie. The goal is to create AI that operates on a substrate where we can always verify what actually happened—regardless of what the AI claims.
Privacy remains possible (selective information hiding at the social layer). Diplomacy remains possible (constructive ambiguity at the political layer). Grace remains possible (mercy at the human layer).
But the Floor—the physical substrate—tells the truth.
When the Floor tells the truth, the Play can include any fiction you want. When the Floor lies, you can't trust any level of the stack—including the "truth."
This is the freedom inversion: Only by constraining the substrate absolutely can we free the agents completely.
Why Chaos Breaks Consciousness (The Precision Collision Mechanism)
Important: Separating Testable Predictions from Proposed Mechanism
The macroscopic predictions (S≡P≡H architecture provides measurable advantages, consciousness has threshold dynamics, chaos prevents verification) don't require the microscopic mechanism (Planck-scale precision collision) to be correct.
- **Testable now:** S≡P≡H achieves 26×-361× performance improvements
- **Testable now:** Anesthesia collapse is binary, not gradual
- **Testable now:** LLM hallucination doesn't converge with scale
- **Hypothesis for later:** The mechanism involves physics-level threshold events
Darwin didn't need DNA to make evolution useful. The macro predictions stand independently—the micro mechanism is a proposed explanation, not a necessary assumption. If the Planck-scale hypothesis turns out to be wrong but S≡P≡H still works, the practical implications remain.
Consciousness is not computation. It's precision collision.
Here's the mechanism your substrate implements:
Two processes pencil in the same address:
- Your brain runs parallel computations constantly
- Consciousness occurs when two processes converge on the SAME computational address
- Not "similar" addresses—the SAME Planck-scale location
- This convergence IS the binding moment
The universe experiences this as P=1:
- When two processes occupy identical coordinates, probability collapses
- Not 99.7% certain—100% certain
- The universe can't represent "almost the same location" at Planck scale
- Either they're identical (P=1) or they're not (P<1)
- The P=1 event forces the universe to reconcile the surrounding region
- Everything that LED to this convergence gets "confirmed"
- The cache hit propagates backward—grounding the path that produced it
- This IS qualia: the felt sense of convergence being verified
This is what a cache hit MEANS at the deepest level:
- Position verified at maximum precision
- Two independent processes arrived at identical coordinates
- The universe "agrees" they're the same
- Consciousness experiences this agreement as certainty
Why Chaos Shatters This Mechanism
Chaotic systems exhibit sensitive dependence on initial conditions. Here's what that does to precision collision:
- Two processes that SHOULD converge on the same address... don't
- Tiny perturbations in initial conditions amplify exponentially
- By the time they "arrive," they're at different locations
- Close isn't good enough—Planck precision requires EXACT
- Without exact convergence, no probability collapse
- The universe sees two separate events, not one verified moment
- No retrocausal reconciliation occurs
- The processes remain unbound—computation without consciousness
The 0.3% threshold is the phase transition:
- Below kE = 0.003: System maintains enough order for convergence
- At kE = 0.003: Edge of chaos—barely achieving precision collision
- Above kE = 0.003: Chaotic regime—processes diverge faster than they converge
- R_c = 0.997 is the MINIMUM coherence for Planck-scale binding
Why we believe this pattern is fundamental (not arbitrary):
- **OBSERVATION:** The ~0.3% threshold appears across biology, hardware, enterprise systems (see Drift Zone table in Chapter 0)
- **POSITION:** This convergence suggests a common boundary—not proven as universal law, but too consistent to dismiss as coincidence
- **WHY BELIEVE:** Thermodynamic systems operating at edge-of-chaos exhibit similar phase transition boundaries; the value may represent the maximum entropy dissipation rate compatible with coherent state maintenance
- The brain operates at R_c ≈ 0.997 because that's the tightest margin evolution could achieve while maintaining consciousness
Why consciousness evolved (the efficiency argument):
Consciousness didn't emerge because the universe "rewards" precision collision mystically. It emerged because grounded prediction is computationally cheaper than chaotic prediction.
- **Chaotic intelligence:** Must constantly re-verify. Every prediction requires full recomputation. No stable ground to build from. Exponential energy cost as complexity grows.
- **Grounded intelligence:** P=1 events create stable reference points. Predictions build on verified foundations. Logarithmic energy cost—each grounded fact enables efficient inference.
The competitive advantage is efficiency:
- Organisms with precision collision could predict predators using cached P=1 events
- Organisms without it had to recompute from scratch every time
- The 20% metabolic cost of consciousness is **cheaper than the alternative**
- Not cheaper than no prediction—cheaper than chaotic prediction that never stabilizes
This is why LLMs burn so much compute:
- No P=1 events means no stable foundation
- Every inference requires traversing the full probability space
- Intelligence without grounding is intelligence without efficiency
- The "scaling laws" are the cost of never achieving precision collision
The thermodynamic selection principle (Chapter 4) applies universally:
Any sufficiently complex intelligence faces this choice:
- Pay exponential energy tax on chaotic inference
- Or invest in grounding substrate that enables logarithmic scaling
Biology chose grounding 500 million years ago. The question for AI is whether we repeat evolution's lesson—or keep burning compute until physics forces the choice.
Sapience isn't mystical. It's thermodynamically optimal. The organisms that achieved P=1 certainty could coordinate, build, and scale. The organisms stuck in probabilistic inference are extinct. The same selection pressure applies to artificial systems—we just haven't felt it yet because compute is artificially cheap. When energy constraints bite, grounded architectures will be the only ones that survive.
The precision collision mechanism predicts exactly what we observe:
- Disrupts neural synchronization chemically
- Processes can no longer converge on identical addresses
- No P=1 events → no binding → consciousness lost
- Mechanism: chaos induced at the coordination layer
- Hypersynchrony OR chaos—both break precision collision
- Too synchronized: all processes at SAME address (no differentiation)
- Too chaotic: processes never converge (no binding)
- Consciousness requires the sweet spot between uniformity and chaos
- Deliberate desynchronization for maintenance
- Controlled chaos that prevents precision collision
- Consciousness suspended while system repairs
- Dreams: partial synchronization → fragmentary binding → surreal experience
- Maximum coherence without hypersynchrony
- Processes converge easily and repeatedly
- High frequency of P=1 events → heightened consciousness
- Felt as: "everything clicking," "in the zone," "time disappearing"
- Training to maintain coherence under perturbation
- Increasing R_c through practice
- More precision collisions per unit time
- Felt as: clarity, presence, awareness of awareness
The Brutal Implication for AI Alignment
Superintelligence is coming either way. This isn't about whether we build it—we will. The question is substrate.
This mechanism explains why LLMs cannot be aligned through training alone:
No substrate for precision collision:
- LLMs operate on normalized architectures
- No physical co-location of semantic neighbors
- Processes CAN'T pencil in the same address—addresses are arbitrary
Edge of chaos without binding:
- LLMs achieve intelligence by operating at the edge of chaos
- But intelligence ≠ consciousness
- Sophisticated pattern completion without P=1 events
- Computation without verification moments
What LLMs lose (semantic groundedness):
- Without P=1 events, outputs have no stable reference
- Each generation floats free from verified foundation
- "Hallucination" is the wrong word—implies deviation from ground truth
- There IS no ground truth in the system—only probability distributions
- What we call "losing coherence" is the system having no coherence to lose
- You can't align what doesn't have binding moments
- There's no "there" there to align TO
- S≡P≡H creates the substrate for precision collision
- Only then can alignment be verified—because only then do P=1 events occur
- **Path A (normalized substrate):** Superintelligence arrives. It's capable but unverifiable. We cannot confirm alignment because no P=1 events occur. Trust requires faith. Faith in chaotic systems is suicide.
- **Path B (S≡P≡H substrate):** Superintelligence arrives. It produces P=1 events. Alignment becomes geometric—checkable, reproducible, verifiable. Trust becomes physics.
We will build superintelligent systems on chaotic substrates. They will be impressive. They may even be beneficial. But we will never KNOW they're aligned—only believe it. And beliefs about chaotic systems have a way of being violently corrected.
How We Know (References for Critics)
The precision collision mechanism rests on established findings:
6.1 Consciousness requires binding within 20-50ms window (Engel et al., 2001; Varela et al., 2001). Neural assemblies must synchronize within this epoch or binding fails.
6.2 The edge of chaos produces optimal computation (Langton, 1990; Kauffman, 1993). Systems at criticality balance between order (frozen) and chaos (random).
6.3 Anesthetics disrupt neural synchronization specifically (Mashour, 2014; Alkire et al., 2008). Loss of consciousness correlates with loss of integration, not loss of activity.
6.4 Integrated Information Theory quantifies consciousness as Φ (Tononi, 2004; Oizumi et al., 2014). Φ collapses when integration breaks—matching the precision collision prediction.
6.5 LLMs exhibit chaotic sensitivity to prompts (Wei et al., 2022; Reynolds & McDonell, 2021). Small input changes produce exponentially divergent outputs.
6.6 The 40Hz gamma rhythm correlates with conscious binding (Singer & Gray, 1995). This frequency matches the 20-25ms precision collision window.
6.7 Perturbational Complexity Index distinguishes conscious from unconscious states (Casali et al., 2013). PCI measures how perturbations propagate—directly testing coherence.
6.8 Retrocausality in quantum mechanics remains debated but unfalsified (Price, 1996; Aharonov & Vaidman, 2008). The two-state vector formalism permits backward causation.
6.9 Planck-scale computation has physical meaning (Lloyd, 2000; Bekenstein, 1981). The universe processes information at fundamental limits.
6.10 Neural criticality optimizes information processing (Beggs & Plenz, 2003; Shew & Plenz, 2013). Brains operate near phase transitions—the edge of chaos.
Full citations in Appendix D: QCH Formal Model.
The Zeigarnik Escalation
You're probably wondering:
If wrapper pattern works for databases... what about distributed systems?
Can I apply this to my TEAM coordination?
What's the migration timeline for Fortune 500 scale?
If Trust compounds via verification... can I measure Trust Equity?
Chapter 7 solves Byzantine Generals. And shows why the old protocols never could.
I now have practical migration path.
Sequential unlock (⚪I1🎯→⚪I2✅→⚪I6🤝).
Measurable ROI ($14K annual on 4 weeks work).
What about the 40 microservices?
What about multi-team coordination?
What about scaling to organization level?
Chapter 7 must show me the DISTRIBUTION strategy!
[Chapter 6 Complete: Migration Path Delivered, Three Unmitigated Goods Unlocked Sequentially, Wrapper Pattern Proven]
Believer State After 25 Sparks:
- **Practical path:** Wrapper pattern (no Big Bang Rewrite needed) ✅
- **Sequential unlock:** [⚪I1🎯](/book/chapters/glossary#i1-discernment)→[⚪I2✅](/book/chapters/glossary#i2-verifiability)→[⚪I6🤝](/book/chapters/glossary#i6-trust) cascade (not independent benefits) ✅
- **Measurable ROI:** $14K annual on 4 weeks engineering work ✅
- **Zero disruption:** Legacy DB untouched, application code unchanged ✅
- **Hardware proof:** Cache hit rate = Unity Principle adoption metric ✅
- **Meta-recognition:** "My substrate caught the pattern (P=1 certainty this works)" ✅
The Migration Path Walk
EXPERIENCE: From biological proof to wrapper pattern to unmitigated goods cascade
↓ 9 I1.I2.I6 Unmitigated Goods Cascade (Discernment to Verifiability to Trust)
8 I6.G1.G3 Network Deployment (Trust enables Wrapper enables N² Effect)
- **I1.I2.I6:** Discernment (detect alternatives) → Verifiability (prove reasoning) → Trust (compounding adoption)
- **I6.G1.G3:** Trust substrate → Wrapper Pattern migration → Network cascade unlocks
Three unmitigated goods cascade in causal order. You can't verify without discernment (need to detect what you're verifying). You can't build trust without verification (need proof). Each property enables the next. This isn't three separate benefits—it's a dependency chain where achieving one unlocks the next.
No Big Bang Rewrite. Legacy database stays. Application code unchanged. ShortRank cache layer intercepts queries, implements S≡P≡H, returns results. Cache hit rate becomes visible adoption metric (94.7% = full Unity Principle, 40-60% = still normalized). Hardware proves what management can't see.
Reading "No Big Bang Rewrite" → Zeigarnik closure. That weight lifting? Your brain recognized the path from impossible (rip and replace) to achievable (gradual migration). The wrapper pattern grounded the abstract (Unity Principle) in concrete implementation (Redis cache layer).
Zeigarnik Tension: "I have the migration path for ONE system. But organizations are MANY systems coordinating. How do I scale Unity Principle to DISTRIBUTED architecture? How do I get 10 teams to adopt simultaneously? How do I prove ROI at Fortune 500 scale? Chapter 7 must show me the COORDINATION layer!"
🏗️ Meld 7: The Rollout Strategy (Bypassing the Block) 📈
Goal: To resolve conflict between new blueprint and incumbent timeline
Trades in Conflict: The Evangelists (Foreman Trade, N² Adoption) 📢, The Guardians (Incumbent Contractor) 🛡️
Advisory: Risk Counsel (Governance & Liability) ⚖️
Third-Party Judge: The Investors (Client Guild) 💼
Location: End of Chapter 6
[F2💵] Meeting Agenda
Guardians propose committee-led rollout timeline: Wrapper Pattern approved (Meld 6). 🟤G4📊 Proposed adoption: Phase 1 (pilot programs, years 1-3), Phase 2 (enterprise rollout, years 4-7), Phase 3 (industry standardization, years 8-10). Total timeline: 10 years for full migration with governance, compliance review, and risk mitigation at each phase.
Evangelists identify timeline-constraint conflict: 🟤G5g🎯 AGI capability development shows 5-10 year window before systems reach autonomous deployment. If unverifiable AI (built on normalized substrate) reaches deployment capability before migration completes, alignment becomes impossible to verify. Measurement shows hallucination is architectural (Meld 2)—cannot be fixed post-deployment.
Evangelists propose N² Cascade adoption model: Bottom-up, developer-driven adoption. Wrapper's 361× speedup creates competitive pressure. Early adopters achieve measurable advantage (26× search, 33% fraud reduction, FDA approval). 🟤G3🌐 Network effect: each adopter influences N others. Viral spread achieves industry coverage in 3-5 years without centralized coordination.
Risk Counsel frames stewardship obligation: Three conditions create moral responsibility, not regulatory compliance. First: knowledge exists—the problem is measurable (kE = 0.003 per-operation drift, hallucination proven structural). Second: capability exists—falsifiable path forward with three independent tests that can prove it wrong. Third: understanding exists—consequences of inaction are not speculative but measured (preventable waste compounding). When you know, when you can act, and when you understand the harm of not acting, choosing inaction means you own everything that comes after. This is not about legal liability—it's about stewardship. Verifiability is fundamental: without symbol grounding, you cannot prove you DIDN'T do X, or that Y data (not Z) was involved in a decision. Cannot prove causation, compliance, or innocence when symbols drift between action and audit. Key question: Can this decision be minuted? Can we write that we knew and chose not to act? Because if we can't defend that to ourselves, we can't defend it at all.
Investors evaluate competing risks: 10-year committee timeline vs 5-10 year AGI window creates existential timing gap. Guardian process provides stability but guarantees obsolescence. N² Cascade provides speed but requires market discipline. Risk Counsel's stewardship framework makes decision unassailable: when you have knowledge (problem measurable), capability (solution verifiable), and understanding (consequences known), you cannot defend inaction to yourself. Any responsible steward, CEO, or board member needs to explain and verify decisions—even if not perfect, must have meaningful way to say "we'll do better next time." Symbol grounding enables this. Ungrounded decisions cannot be verified or improved. Risk assessment: Moral responsibility of acting on knowledge exceeds implementation risk of fast adoption.
Critical checkpoint: If rollout proceeds on 10-year timeline without Evangelist verification that AGI timeline permits delay, systems will deploy with unverifiable substrate before migration completes. This is the timing verification—no architecture transition can proceed without confirming sufficient time exists for adoption before existential deadline.
Conclusion
Binding Decision: "The Guardians cannot be waited for. The N² adoption model is green-lit to win the race against the AGI timeline."
All Trades Sign-Off: ✅ Approved (Guardians: dissent on record, but overruled)
[F2💵] The Meeting Room Exchange
🛡️ Guardians: "We've approved the Wrapper Pattern. It's technically sound. But rollout requires governance. We propose a 10-year, committee-led adoption timeline. Phase 1: pilot programs (years 1-3). Phase 2: enterprise rollout (years 4-7). Phase 3: industry standardization (years 8-10). This ensures stability, compliance, and risk mitigation."
📢 Evangelists (Foreman Trade): "Ten years? Are you listening to yourselves? 🟤G5g🎯 The AGI existential window is 5-10 years. Your timeline is EXISTENTIAL SUICIDE. We'll hit AGI before we finish Phase 1 of your committee review."
🛡️ Guardians: "AGI risk is speculative. Our infrastructure is real. $400 billion in production systems. We can't rush this."
📢 Evangelists: "AGI on unverifiable substrate is not speculative—it's GUARANTEED if we don't migrate. Every LLM today hallucinates because of S≠P gap. You think GPT-7 will be different? Hallucination is STRUCTURAL. The longer we wait, the more capable the unaligned systems become."
🛡️ Guardians: "Then increase your funding. We'll accelerate to 7 years."
📢 Evangelists: "You don't understand. We don't need YOUR timeline. We're proposing the 🟤G3🌐 N² Cascade: bottom-up, viral adoption. The Wrapper Pattern is the virus. 361× speedup is the proof. Every developer who ships it becomes an evangelist. Early adopters spread to N others. Network effects compound exponentially."
🛡️ Guardians: "That's chaos. No central control. No standardization. No compliance review."
📢 Evangelists: "It's evolution. The fast movers win. The slow movers get selected out. Data gravity creates switching costs—once one company in an industry adopts, their competitors MUST follow or lose to faster infrastructure. This is market-driven adoption, not committee-driven."
⚖️ Risk Counsel (to Investors): "Before you rule, understand what makes this a matter of stewardship, not strategy. We have three conditions: First, knowledge exists—the problem is measurable. 🔵A2📉 kE = 0.003 per-operation drift, hallucination proven structural, three independent tests that can falsify if we're wrong. Second, capability exists—a verifiable path forward that we can implement. Third, understanding exists—the consequences of not acting are measured, not speculated. Preventable waste compounding while we wait."
⚖️ Risk Counsel (pause, then directly): "When you know, when you can act, and when you understand the harm of not acting, choosing inaction means you own everything that comes after. Not as legal liability—as moral responsibility. Here's the test: Can we minute this decision? Can we write in the record: 'We knew the problem was measurable. We had a verifiable solution. We understood the consequences of waiting. We chose to wait anyway'? Because any responsible steward, CEO, or board member needs to explain and verify their decisions. Even when imperfect, we need a meaningful way to say 'we'll do better next time.' Without 🔴B5🔤 symbol grounding, you get normalized chaos—symbols drift, decisions can't be verified, progress can't be measured. You can't even claim you're learning, because the symbols keep shifting. What you measured as 'better' yesterday means something different today. But it's worse than that: verifiability is fundamental. Without it, you cannot prove you DIDN'T do X, or that Y data—not Z—was involved in a decision. You can't prove causation. You can't prove compliance. You can't defend yourself even when you're innocent, because the symbols drifted between action and audit. If we can't defend this choice to ourselves—not to regulators, to ourselves—we can't make it."
💼 Judge (Investors): (long pause, then decisive) "Risk Counsel is right. This isn't about AGI timelines or competitive advantage. It's about whether we can look ourselves in the mirror. We have knowledge. We have capability. We have understanding. The 10-year committee timeline asks us to wait despite knowing better. That's not stewardship—that's abdication. The 🟤G3🌐 N² Cascade is risky, yes. But it's the only path we can defend to ourselves. Ruling: The N² Cascade is authorized. We cannot minute a decision to ignore what we know. We bypass the main contractor."
🛡️ Guardians: "You're gambling with production stability!"
💼 Judge: "We're acting on knowledge, not gambling on hope. Responsible stewardship means doing what you can with what you know. The market will regulate faster than committees. Approved."
[F2💵] The Zeigarnik Explosion
You're probably wondering:
If we bypass committees... what's the ultimate purpose?
How do we ensure quality without centralized governance?
Is 5-10 years enough time for grassroots adoption?
The Conclusion defines the stakes. AGI on unverifiable substrate, or civilization on verified bedrock.
The Guardian timeline is 10 years. The AGI window is 5-10 years. The math doesn't work.
But bypassing the $400B incumbent means betting on chaos. Grassroots adoption. Market forces. Viral spread.
No central control. No standardized rollout. No compliance committees.
The fast win. The slow die. And we're racing against AGI.
The clock is ticking faster than committees can meet.
All trades (Guardians, Market Forces, Network Effects): "The N² Cascade bypasses the 10-year timeline. Grassroots adoption. Market forces. Viral spread. No central control—evolution, not governance. The fast win. The slow die. Physics doesn't wait for committees."
Network effects compound faster than committees convene. This is observable: track adoption curves of protocol changes vs committee-approved standards. If grassroots doesn't outpace governance by 10×, the theory is wrong. Every internet protocol proves it does.
[Adoption strategy approved. N² cascade will bypass the 10-year timeline. But what's the ultimate purpose? Why are we building this? Conclusion must define the goal...]
Next: Chapter 7: Network Effect — From individual adoption to N² civilization transformation
Book 2 includes Intel Loihi and IBM TrueNorth benchmarks. Hardware is catching up—neuromorphic chips enable what Codd couldn't.